Copyright © 2026
Adaptive ML, Inc.
All rights reserved
Privacy PolicyAdaptive ML, Inc.
All rights reserved







Adaptive Engine: The Post-Training Platform for Production-Grade Specialized Models
.png)
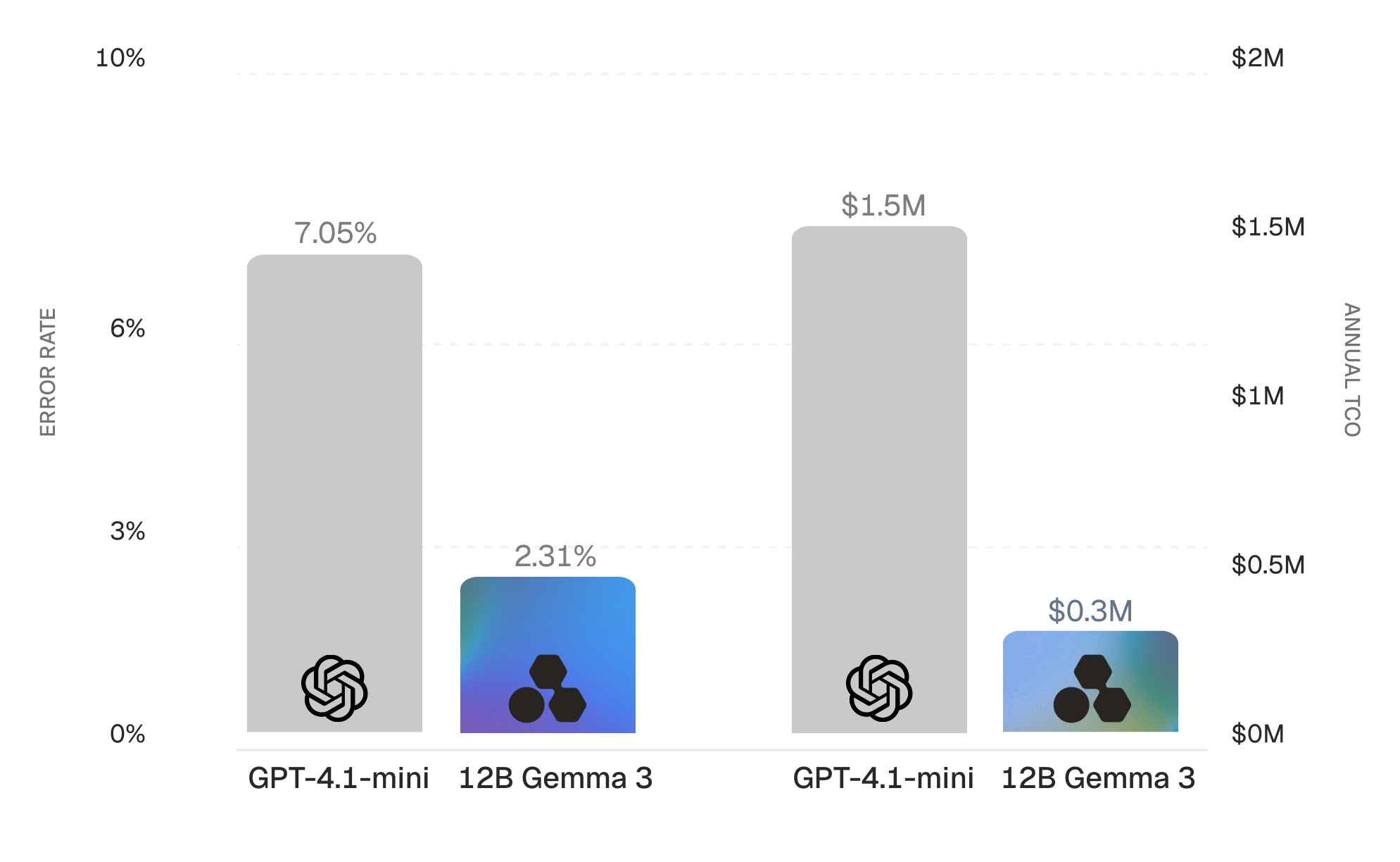
One of the world’s leading telecom providers summarizes roughly 600,000 customer care calls a day using a 12-billion parameter Gemma 3 model, fine-tuned on their data and running on their infrastructure. The model it replaced was GPT-4.1-mini, selected for its cost–performance tradeoff on this task. On judge-evaluated accuracy, the fine-tuned model scores 97.69%, nearly five points higher on the same benchmark.
The result that matters most is not the benchmark delta. It is that the model runs inside their system, trained on their data, and improved using production feedback on their timeline. The organization owns the model, the training pipeline, and how it evolves over time.
While frontier models are powerful, they come with limits that matter at enterprise scale: accuracy that plateaus short of what the task demands, cost that grows with volume, throughput that depends on a provider’s capacity allocation, and missing capabilities like compliance-grade redaction that the workflow requires. There is a better pattern for these workloads: train a smaller model on your task, with your data, using real production feedback as the learning signal. The result is often a model that outperforms a frontier model on that task, runs at a fraction of the cost, and does tasks the general model was never built to do.
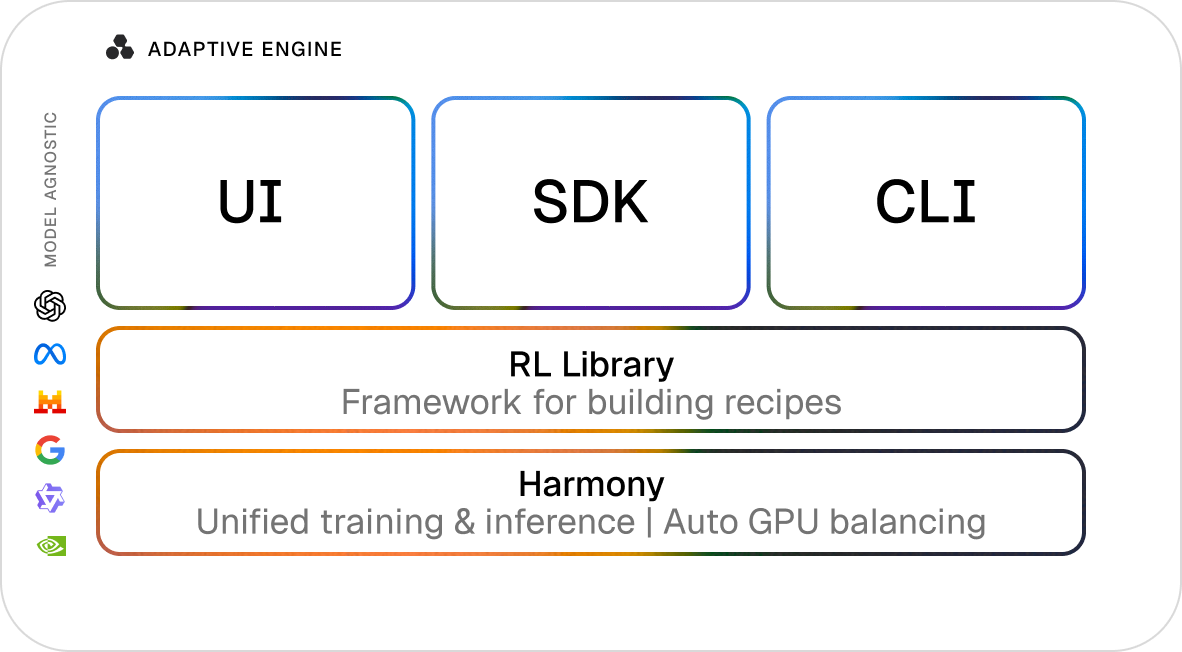
Adaptive Engine is the infrastructure layer for this pattern. It is an end-to-end post-training and inference system for running reinforcement learning on production workflows, where models are continuously improved using real task feedback. It unifies training, inference, evaluation, and deployment so that iteration is a single loop rather than a sequence of disconnected systems.
The rest of this post explains why that matters in practice.
Post-training has moved quickly. GRPO, DPO, PPO, and GSPO are widely available, and most teams can get a basic RL loop running in a notebook.
The constraint shows up when moving from experiments to production systems.
In practice, the bottleneck is not the algorithms but the infrastructure around them. Over the past two years, we have seen this pattern consistently across deployments at enterprises like AT&T and Manulife.
Online RL methods generate outputs during training, not beforehand. Every step requires inference from the current model to produce rollouts that are immediately used for optimization.
When training and generation run on different systems, even within the same cluster, you end up with outcomes like log-probability mismatches between them. The discrepancy looks small, but it compounds across training steps, degrades the learning signal, and in severe cases can lead to model collapse. Training appears to proceed normally, but improvements are unreliable and debugging can take months. This is not a configuration problem but an architectural one. We built Harmony, the framework underpinning Adaptive Engine, as a single codebase for training and inference largely because of this constraint.
Most RL systems fail here because training and inference are treated as separate systems.

In traditional split architectures, teams face a tradeoff. Synchronous RL is simple but slow: every sample must finish before training can continue, and a handful of straggler rollouts hold up the entire batch while training GPUs sit idle. This is especially painful for agentic tasks like multi-turn tool use, where long-tail latency distributions make stragglers common.
Async RL is the standard workaround: generate rollouts on a slightly stale copy of the model so training does not have to wait. But stale weights introduce off-policy noise that hurts training dynamics, and the system now requires careful tuning of how many GPUs to dedicate to inference versus training.
With Harmony this tradeoff is largely avoided. The system dynamically allocates GPUs between training and inference. As shorter rollouts finish, those GPUs can begin producing gradients while longer-running generations continue. This absorbs variance in rollout length without introducing off-policy updates. The training signal stays consistent, and the system stays simpler.
RL is only as good as its reward signal. For tasks with verifiable outcomes, that signal can be made concrete.
When a telecom provider trains a model on call summarization, evaluation is not a single metric. It spans faithfulness to the transcript, extraction of key details, structured formatting requirements, and domain-specific classification.
Each measure maps directly to a production constraint the system must satisfy.
Adaptive Engine supports several types of graders:
The same grading function runs in development, training, and production. If these signals diverge, optimization diverges from business reality.
Some teams run on fully managed infrastructure. Others operate in isolated environments across AWS, GCP, Azure, or on-premises due to regulatory constraints or sovereignty requirements. Fully air-gapped deployments are also supported.
Training and inference run together, with compute allocation dynamically managed at runtime. This avoids the need for manual partitioning of GPUs between training and serving workloads.
A typical improvement cycle follows three steps using a combination of production data and curated or synthetic datasets:
What teams learn about reward shaping, grader design, and training stability gets encoded in the recipe library and reused across deployments.
Instead of maintaining separate systems for training, evaluation, and serving, teams operate a single feedback loop where production behavior directly drives model improvement.
This is most valuable in high-volume, repetitive workflows such as call summarization, classification, OCR, and customer support automation. Many of these systems also include agentic components, where multi-step interactions introduce additional variance. In these environments, throughput is measured in millions of decisions, latency matters, and every percentage point of accuracy has a dollar value.
At a volume of 600 thousand calls per day, the shift looks like this:
.png)
The fine-tuned Gemma 3 model outperforms GPT-4.1-mini not because frontier models are inadequate, but because a model trained on the right task with real feedback has a structural advantage on that task.
The more important metric is the direction of improvement. A model that improves from production feedback behaves more like infrastructure that appreciates over time. The value accrues to the organization that builds it.
The telecom provider’s model is better this month than it was last month. It already handles 600,000 calls a day with higher accuracy, better compliance, and structured outputs the previous system could not produce. Production signals feed directly into training, and the model improves on the task your organization actually runs.
For teams building these systems, Adaptive Engine provides a single integrated post-training system that connects data, training, evaluation, and deployment in one loop. It includes the underlying Harmony runtime for unified training and inference, a grading system for defining production-aligned reward signals, and a recipe-based interface for running and iterating on RL workflows in production.
For the engineering deep-dive on how Harmony works under the hood, or to see Adaptive Engine on your data, talk to our RL team.