Automated, scalable evaluations grounded in your guidelines







Automated, scalable evaluations grounded in your guidelines

Overview
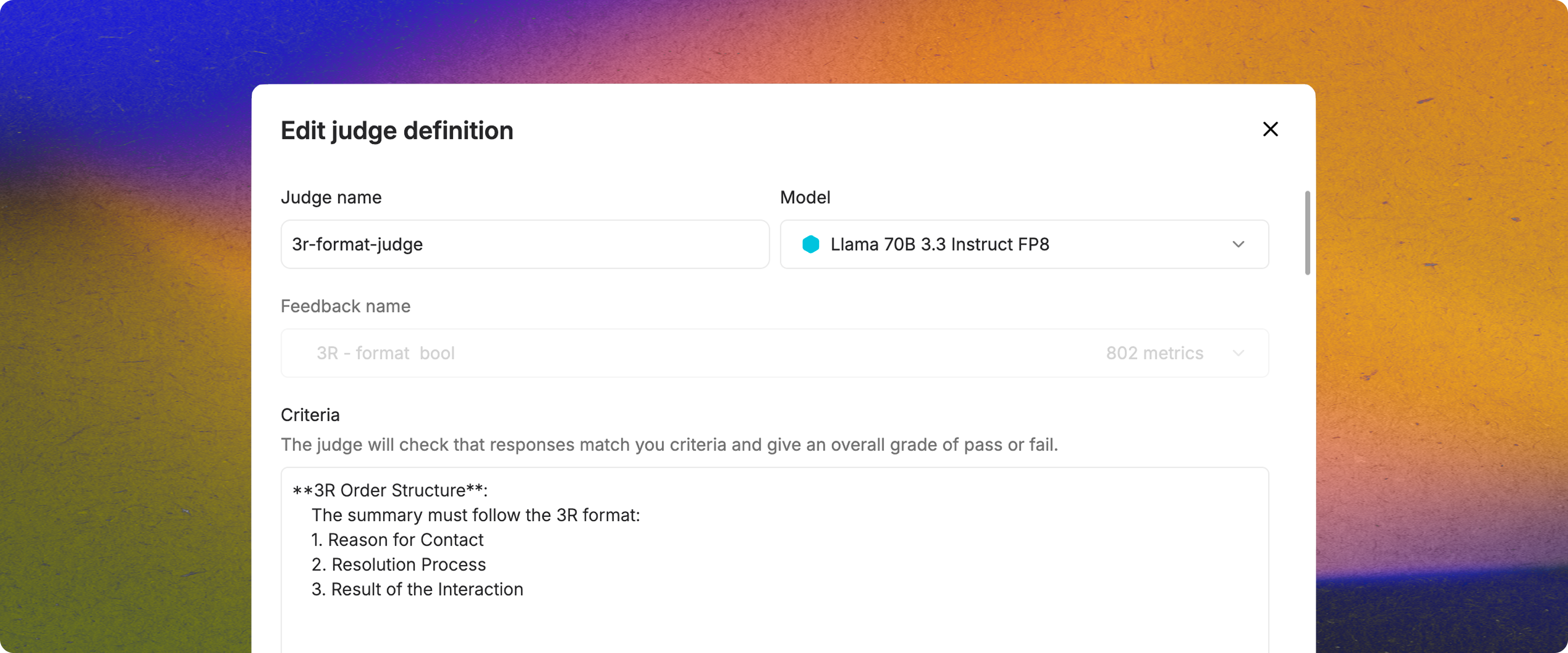
AI Judges offer a practical solution: use one model to evaluate another.
As LLMs become more capable, evaluating their behavior becomes more complex. Traditional metrics can’t assess whether a model followed instructions, used the appropriate tone, or produced a safe and helpful response—and relying on human reviewers doesn’t scale.
Adaptive ML’s AI Judges translate your behavioral guidelines into structured, automated evaluation criteria. For each model output, they generate a scalar score and a clear explanation detailing reasoning behind the judgment.
By outsourcing evaluation, they make it possible to deliver fast, consistent feedback across thousands of examples.
AI Judges enable scalable, cost-effective evaluation with little to no dependency on human annotation.

Why it Matters
Tune and evaluate models on the KPIs that actually matter to your business.
AI Judges make evaluation measurable, repeatable, and predictive of production performance. They:
• Replace or supplement human feedback with automated, rubric-driven scoring
• Evaluate nuanced model behavior—like faithfulness, answer relevancy, and context relevancy
• Accelerate iteration by delivering fast feedback during training and experimentation
• Provide structured reward signals for reinforcement learning pipelines
The result is faster iteration, clearer insights, and models that are rooted in your own rubric.