







Overview
For enterprise use cases, specialization is the key to production-grade accuracy and reliability.
For optimal performance, LLMs should be task-specific, fine-tuned for the unique behaviors and specifications of each use case.
However, larger organizations might have dozens, if not hundreds, of LLM-based workflows, making full model fine-tuning a daunting prospect.
Adapters are the answer to this efficiency problem. LoRA (Low-Rank Adaptation) adapters are small, trainable low-rank matrices that can be swapped in or out of a shared model backbone.
During LoRA fine-tuning, the weights of the original model are ‘frozen’, only these smaller matrices are tuned, making it far more efficient than full-model training.
Users can train different LoRA adapters for different tasks, switching seamlessly between them without reloading the base model.

Why it Matters
Adapters allow a single LLM to specialize into many scenarios, reducing GPU requirements.
But, that’s not all. Because the base model’s pre-trained weights never change, the model’s general knowledge remains intact, helping protect against catastrophic forgetting.
Additionally, training just the adapters reduces overfitting on small datasets and makes rollbacks trivial—just unload the adapter.
With the right infrastructure set-up, LoRa adapters can also be used for on-the-fly specialization at inference time.
A running service can hot-load several LoRA adapters, choosing one per request or even merging them, without keeping multiple full models in memory.
This cuts serving costs and simplifies A/B testing or personalization workflows.
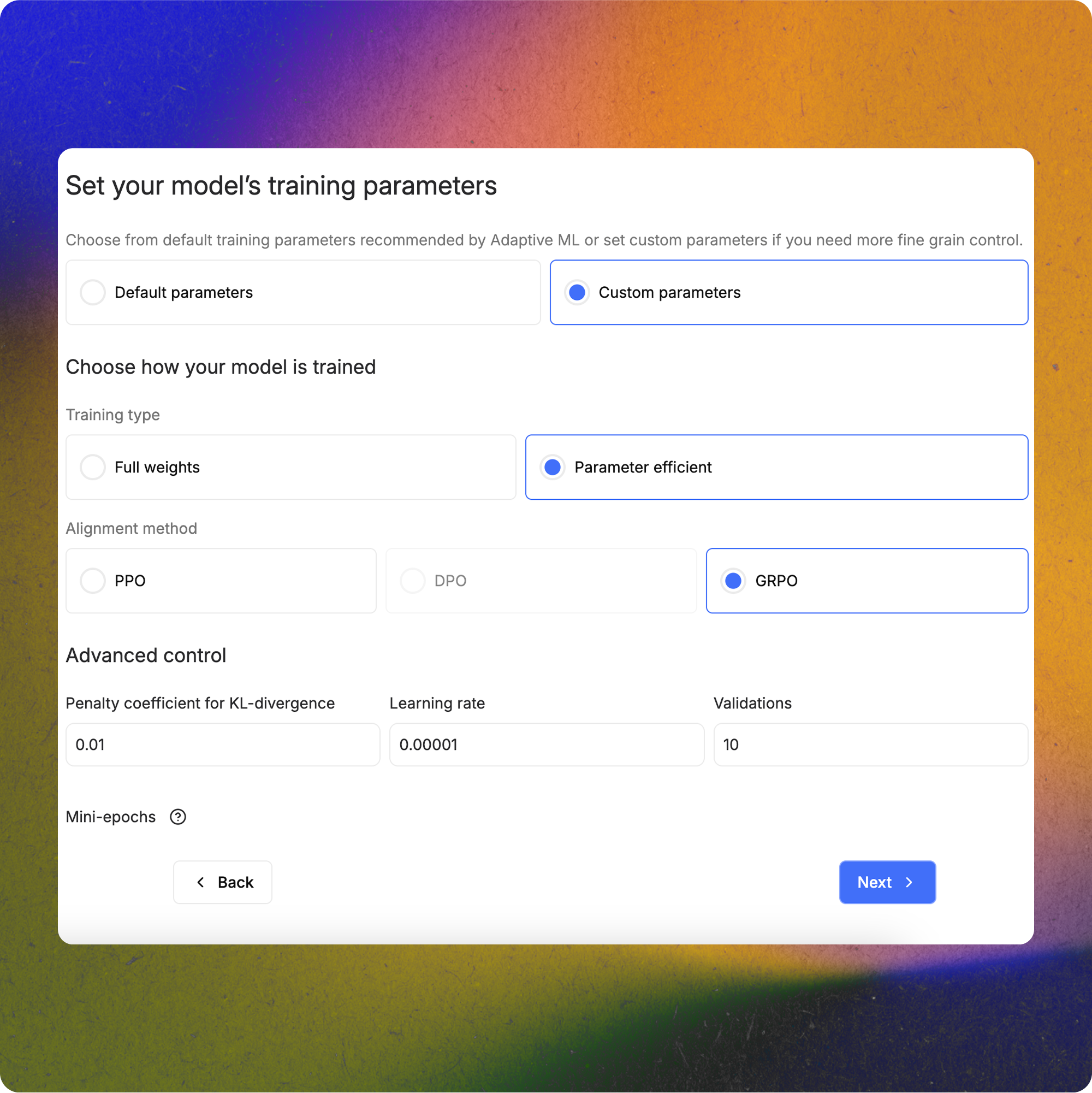
With Adaptive Engine, users can reinforcement fine-tune hundreds of lightweight adapters on a shared model backbone, maximizing both efficiency and performance.
Anytime a training run is initiated, users have the option of running a full-weight training or a parameter-efficient adapter training.
This can be done in the ‘training parameters’ section of the Adapt menu.
Learn more about adapter tuning in our documentation.


