Copyright © 2026
Adaptive ML, Inc.
All rights reserved
Privacy PolicyAdaptive ML, Inc.
All rights reserved







Prompting, SFT, and RL in production systems
.png)
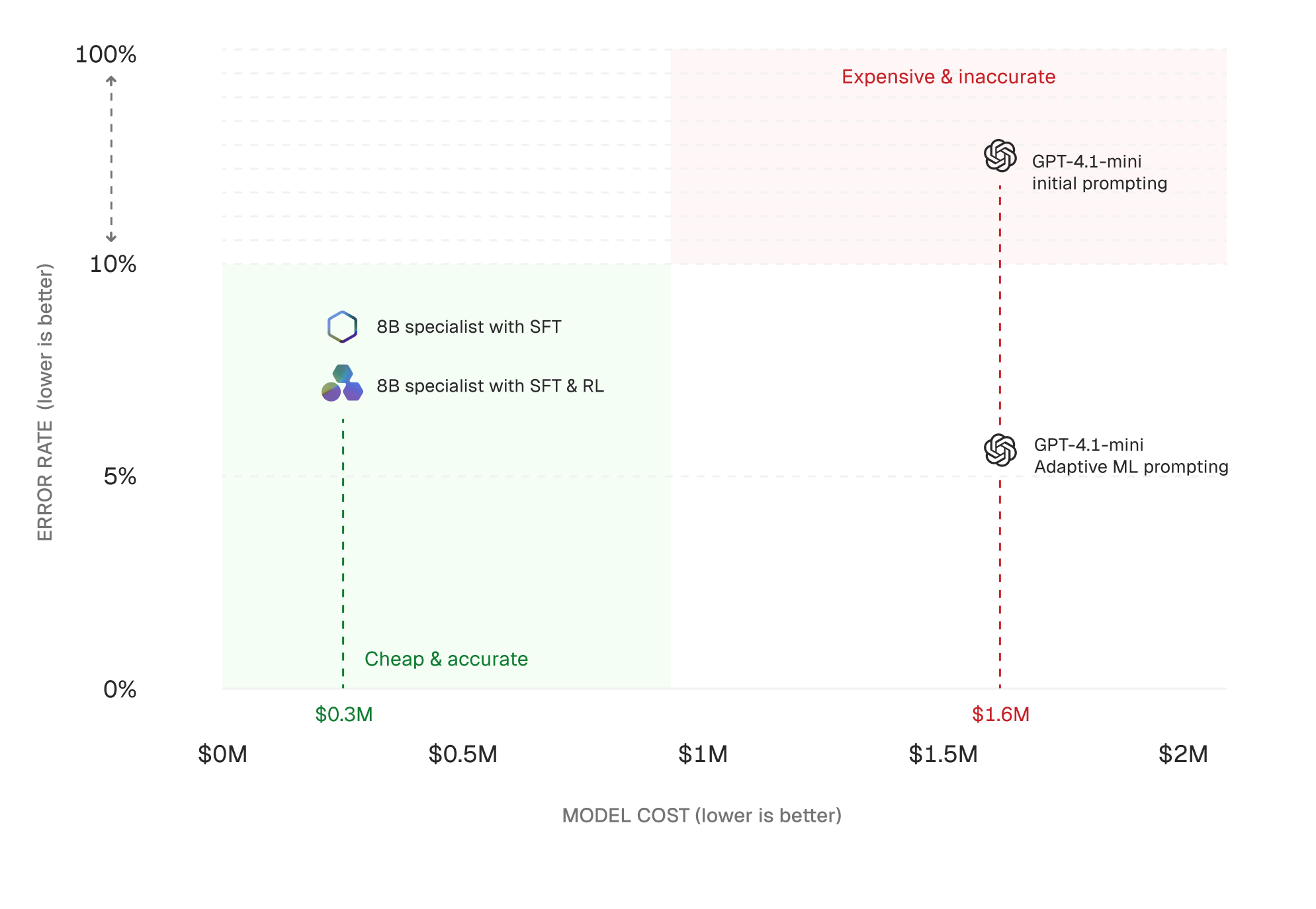
A Fortune 500 customer-operations team we work with migrated a high-volume LLM workload from a frontier model to an open 8B-parameter specialist model they customized. They first trained it using supervised fine-tuning (SFT), then further improved it with reinforcement learning (RL).
.png)
Annual cost dropped by approximately 80 percent. The ratio varies with serving configuration, but the structural shift is consistent: specialization decouples cost from frontier pricing.
The sequence that produced the results, prompting, SFT, and then SFT+RL, reflects a recurring progression in production LLM systems as they transition into high-volume, specialized workloads.
RL is often discussed in the context of agentic systems, where models act over multiple steps and outcomes can be evaluated across trajectories. That is a natural fit, and we will cover it separately. This piece focuses on a more immediate question: how to evaluate prompting, SFT, and RL as techniques for building and improving production LLM systems.
Prompting, SFT, and RL are not interchangeable. Each addresses a different constraint as a workload develops, specializes, and scales.
.png)
Prompting defines behavior at runtime. SFT moves repeated behavior into weights through demonstration. RL updates behavior based on outcomes measured by a reward signal: a verifiable task, a LLM-as-judge model, or a hybrid scoring system.
Prompting is always present. The question is whether prompting alone carries the system, or whether the system also needs training (SFT, RL, or both) to do its work.
Production systems often start with prompting.
In the workload above, prompt engineering increased accuracy into the 90% range and improved structural validity from 59% to 100% by tightening schema constraints and clarifying field definitions.
That level of improvement is often sufficient early on. Many teams stop here.
Prompting is optimal when:
However, prompting has structural limits that emerge as systems scale.
When these limits start to dominate, the system has to move from instruction to training.
SFT becomes effective when the desired behavior can be demonstrated repeatedly and stays stable across production traffic. It is the most common form of post-training in production today.
Common workloads include:
In these cases, SFT compresses repeated behavior into model weights. Structure no longer needs to be re-specified at inference time.
In the Fortune 500 example, the 8B SFT-trained model achieved approximately 91 percent accuracy while reducing cost by roughly 80 percent. This is the core economic effect of specialization: performance concentrates on the target distribution; cost decouples from frontier models.
But SFT introduces structural limits:
SFT is strong for stable tasks, weaker when correctness depends on evolving definitions or long-tail behavior. For high-volume specialized workloads, SFT is the foundation, not the end state. SFT establishes baseline behavior from demonstrations. RL extends that baseline by training against outcomes the demonstrations could not enumerate. The two are complementary: SFT to mimic, RL to generalize and reason.
RL becomes necessary when correctness can be evaluated after execution but not enumerated in advance.
Reward signals are often implicit rather than missing. If a team can define what "good" looks like in a way that can be evaluated consistently, the reward signal already exists. The work is making it explicit, stable, and trainable.
Instead of learning from fixed input-output pairs, the model learns from whether its outputs succeed against a reward signal. The shift is structural: the system no longer depends on enumerating correct behaviors. It depends on whether outcomes can be evaluated reliably.
This pattern appears wherever correctness is testable:
In these cases, RL does something fundamentally different from SFT. It does not imitate examples. It optimizes for outcomes against a reward signal defined in the real system.
SFT and RL are usually presented as separate techniques. In practice they are endpoints on a continuum that includes SFT on synthetic data, distillation from a stronger teacher, DPO against preference data, off-policy RL, and RL with judge models. Most production systems draw from several.
For each module in your system, a useful starting question to ask is: can you write the correct answer, or can you reliably score it?
That definition step is real system design work. It determines whether a system stays static or becomes continuously optimizable.
Agents are where RL becomes inevitable.
With agents, the model doesn’t produce a single output. It reasons, acts, observes results, and repeats.
Each step leaves a trace:
RL operates directly on this structure. Instead of training on isolated examples, the system assigns reward signals to entire trajectories. Those signals come from rule-based checks, tool execution outcomes, or judge models scoring task success.
This closes a feedback loop that prompting and SFT do not capture. Production agent traces get scored and fed back into training, improving the policy that governs the system.
Agents make the underlying pattern visible: outcomes can be evaluated but not enumerated. Systems that cannot turn their own trajectories into training signals eventually plateau.
These technical differences translate directly into system-level behavior:
The team we opened with did not adopt RL as a discrete choice. It reached post-training as a consequence of its workload.
Prompting defined early behavior. SFT stabilized it. RL extended it in directions demonstrations alone could not reach. For specialized production workloads at scale, this is not an edge case. It is the trajectory.
The question is not whether systems will move beyond prompting. It is how quickly teams can build and scale post-training into their production workloads.
Adaptive is the post-training platform for enterprise LLM systems. We help teams build and deploy specialized agents using SFT and RL, with the infrastructure to train, evaluate, and improve them in production.