Copyright © 2026
Adaptive ML, Inc.
All rights reserved
Privacy PolicyAdaptive ML, Inc.
All rights reserved







Agents Explained | A Visual Primer

Everyone is talking about agents. Hardly a week goes by without major AI labs announcing an impressive agent demo or an agent toolkit. They've enabled many to vibe-code their way to internet fame, and they are the subject of endless social media commentary. But, what are agents exactly? How are they built and trained?
In this blog post we'll cover the mechanics of agents, or how you get from a pure text-generator (a base LLM) to something that can take real-life actions. We'll walk you step by step through an example you can follow along, then cover what advances in the field made agents effective in recent months. Here's the workflow we'll explore together—you can click through to see each step:
get_weather to check conditions, then web_search for activities.
{
"name": "get_weather",
"arguments": {
"location": "Copenhagen, Denmark",
"unit": "celsius"
}
}
{
"name": "web_search",
"arguments": {
"query": "weekend activities Copenhagen cloudy weather"
}
}
So what is an agent? A good definition is: an LLM using tools iteratively in a loop to achieve a goal. Tools define code the agent can execute, analogous to the functions a programmer would call. This is why LLMs that can use tools are sometimes called "function-calling". Tools can do two things: retrieve useful information, like performing web searches or looking through your files; and change the state of the world, like ordering groceries or sending an email. The agent achieves its objective by interleaving multiple rounds of reasoning and tool calling, and by maintaining context (memory) about its progress towards its objective.
Suppose you are in Copenhagen for a few days and ask an agent to plan your weekend trip.
The agent doesn't immediately respond. Instead, it first reasons about what information it needs to complete your request. In response to your query, the agent will reason about your question and the information it needs to complete the task, similar to how reasoning models approach a complex problem by decomposing it into a few steps.
get_weather
to check conditions, then
web_search
for activities.
The agent will then execute its plan, which might involve getting information about the weather or upcoming events.
{
"name": "get_weather",
"arguments": {
"location": "Copenhagen, Denmark",
"unit": "celsius"
}
}
However, the only thing LLMs can read and write are tokens. We need a way to translate tool information and calls to a list of tokens. In agents, this is done in a similar way as with chatbots, where conversations are encoded as a list of turns (each message exchange between user and assistant) with associated roles (system, user, assistant).
To convert from a list of turns to a sequence of tokens, the application will use the model's chat template, a specialized piece of code shipped with the model (for instance on Hugging Face or Github for open models). In our example, we are applying the Qwen 3 chat template to the reasoning stage:
get_weather
to check conditions, then
web_search
for activities.
The specific chat format depends on how the model was trained, but this usually involves separating each turn with special tokens and annotating the turn type at the beginning (system, user, assistant). For reasoning within the assistant turn, the model uses special <think> tags.
Tool names and definitions are added to the system turn (not shown in our visualization), so the model has them in context and can decide to use them as needed. Tool calls need to be formatted as structured outputs (dictionary in JSON format) and placed within <tool_call> tags (for our Qwen 3 example; chat templates differ significantly on tool formats).
The special end-of-turn token is used to signal that the LLM should stop generating, at which point the user should be queried or tools should be executed using the arguments provided in the tool JSON. Here on the right, we see the concatenation of tool call and response at the token level:
{
"name": "get_weather",
"arguments": {
"location": "Copenhagen, Denmark",
"unit": "celsius"
}
}
The weather looks warm but partly cloudy this weekend, so the model could search for scenic landmarks, by using an internet search tool and reading the content of retrieved web pages:
{
"name": "web_search",
"arguments": {
"query": "weekend activities Copenhagen cloudy weather"
}
}
The agent will then have enough information to give you a few alternatives on how to best enjoy the city.
You might have also heard about MCPs in the context of AI agents. MCP (Model Context Protocol) is a standard that allows developers to define tools for their application in a common format. It is a commonly agreed upon interface for agents to access app functionality, whether that be access to calendar apps, web searches, databases, or actions with workplace software like Slack or Linear. By making an MCP to connect to their apps, developers ensure most agents will be able to access them automatically without further tuning.
The example above shows that building agents interacting with the real world through software tools is actually quite straightforward. So why did we have to wait for 2025 to have functional agents?
Simply put, two things needed to happen. Let's examine each ingredient in turn. First, pretraining on large-scale datasets was required to teach models general-purpose knowledge about all human activities. But pretraining is not enough, otherwise we would have seen good agents as early as 2023. The second ingredient was large-scale reinforcement learning (RL) on LLMs with reasoning, tool use and long interactions.
Discussions about agents are not new: the term originates from RL research dating back to the 1990s. RL agents from before the LLM era managed to grab some impressive achievements in games or specialized robotics. These successes demonstrated that RL could produce sophisticated behavior in constrained environments. However, all attempts to create the kind of general-purpose agent that can complete useful tasks on your behalf proved elusive. This is because these agents were trained from scratch, having to learn, for instance, to fill a text field in a browser by performing random actions. Building agents on top of LLMs, which possess knowledge of the world, eliminated this problem.
However, a base LLM is not an agent. Base LLMs, immediately after pretraining, will not even reliably follow your instructions: they simply complete text in the way that most resembles their training data (web pages and books). Hardly good behavior for tool calling! Making LLMs usable, either as chatbots or agents, requires extensive post-training. In recent years, the post-training pipeline of all foundation models, whether frontier or open-source, has started to include increasingly more agentic training done with RL, including both reasoning and tool use. For instance, see Qwen 3's training pipeline below:
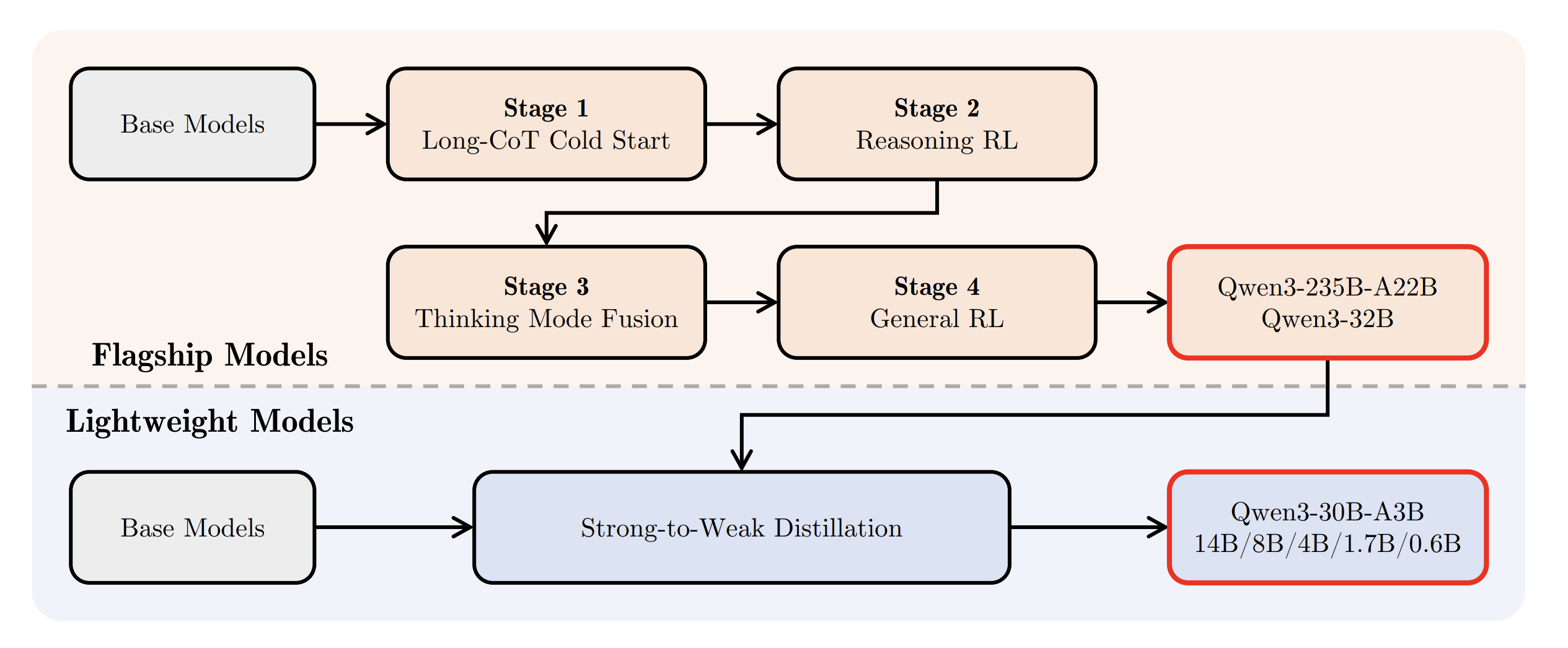
Training agents to reason involves prompting the model to use additional tokens to think through the task step by step (chain-of-thought prompting) before giving its final answer, scoring this answer and using RL to update the model accordingly. The emergent reasoning abilities that RL and chain-of-thought provide together were famously demonstrated when models spontaneously learned to verify their own reasoning—what DeepSeek called the "aha" moment—without being explicitly trained to do so.
Tool use training involves letting models access tools, hosted on dedicated machines during training, to complete tasks. Feedback from tool execution (did the model use the tool correctly?) and task completion (was the task solved?) are used as training signals and allow the model to improve and reach increasingly sophisticated behavior. These post-training pipelines have powered impressive and sustained progress on agent abilities in the past year, making them effective at exponentially longer tasks.
Now that we understand how agents work technically, what challenges remain for real-world deployment? Today's agents excel at using openly available tools in general-purpose contexts; however they struggle to adapt to specific environments, like using domain-specific knowledge or specialized tools. Building personalized assistants that can integrate deeply into your business processes will take additional work. RL taught LLMs to act as students, able to complete hard but artificial tasks. In the future, it will have an outsize role in teaching them to act as skilled and effective collaborators in the workplace.
To learn more, check out our work with agents.