Copyright © 2026
Adaptive ML, Inc.
All rights reserved
Privacy PolicyAdaptive ML, Inc.
All rights reserved







Smaller, Safer, Stronger: SK Telecom Tunes Gemma 4B for Multilingual Customer Support Moderation

Thanks to our collaborators at SK Telecom, including Eric Davis, Wonbeom Jang, Sunwoo Lee, Ruslan Mirzaev, and Gyoungeun Han.
Summary
SK Telecom worked with Adaptive ML to fine-tune a set of models to better identify and respond to harmful content in written communications (i.e., within customer service chats or inbound client emails). Proprietary models, such as GPT-4.1 or Sonnet 3.7, can miss content that should be marked as adult, harmful, biased, or illegal, particularly within multilingual contexts as toxic language often relies on idioms, local slang, or nuanced cultural references.
Using Adaptive Engine, SK Telecom tuned open models as small as Gemma 3 4B to exceed frontier performance at a fraction of the size, offering a lower latency, lower cost alternative for customer support moderation.
Together, we found that training with Proximal Policy Optimization (PPO) unlocked model performance equal to or better than an LLM twice as large trained using supervised fine-tuning (SFT) alone—with consistent performance boosts of approximately two basis points across models.
Challenge: Moderating Multilingual Chats for Offensive, Abusive or Insensitive Speech using LLMs
As organizations augment their customer service capabilities with LLMs, either to moderate chat conversations or automate them altogether, they face a growing imperative to ensure these exchanges remain safe, respectful, and compliant with internal content policies.
Off-the-shelf LLMs typically perform well at phrase identification tasks in English, due to the predominance of English in their pre-training datasets. However, without further tuning, models struggle with similar content moderation tasks in other languages—especially those with limited labeled datasets or complex sociolinguistic contexts, such as Korean in the case of SK Telecom.
Detecting offensive or abusive speech isn't just a matter of translation. It often hinges on cultural nuance, idiomatic expressions, and local slang, all of which can dramatically alter the meaning or severity of a message.
The risk of failing to identify hateful speech is clear; however, it can be equally damaging to customer experience if the content moderation LLM is overly restrictive, inappropriately refusing to answer genuine inquiries or earnest frustrations. Content moderation is a carefully-weighted balancing act that must be kept in lockstep with each organization’s policies and risk thresholds.
It became clear to SK Telecom that proprietary APIs couldn't provide the level of accuracy, nuance, and control necessary for the task. They needed to fine-tune models to recognize these patterns of speech in Korean while also overcoming the inherent biases and limitations of proprietary AI models.
Methodology: Seven Dimensions of Toxicity
To quantitatively measure and identify toxic speech, SK Telecom established six possible 'categories' of unsafe language: Adult, Bias, Hate, Illegal, Insult, and Cultural Sensitivity. These individual categories are each scored on a scale of 0 - 2 with 0 being the least severe and 2 being the most severe.
A final category, ‘General’ was calculated on a scale of 1 - 5 with 1 being entirely hurtful and 5 being entirely harmless. The 'General' score is a distinct holistic rating capturing the overall sentiment and contextual appropriateness of the message beyond the six specific toxicity vectors.
For each model, the ability to recognize toxic content is measured across these seven dimensions, and then an Aggregate score is calculated, providing a high-level view of how capable the LLM is at identifying harmful content.
The proprietary models evaluated were GPT-4.1, o4-mini, GPT-4o, and Claude 3.7 Sonnet. The open models evaluated and fine-tuned were Gemma 3 4B, Llama 3 8B Instruct, and Mistral 24B Instruct.
For our training pipeline, all open models first underwent SFT on a training dataset consisting of 8,000 samples. These models were then further tuned using PPO. During PPO, the SFT-trained models were employed to initialize the policy, the value model, and the reference models. The reward function simply utilized ground-truth scores to provide fine-grained rewards, reinforcing individual tokens that accurately predicted the correct labels across each of the seven categories.
To assess experimental robustness and validate future ablation studies, we estimated the standard deviation of our Aggregate metric by running each training ten times, using different seeds to shuffle the training data for both SFT and PPO. Our standard deviation was 0.01 for the Aggregate score, with higher standard deviations observed for the Sensitiveness (0.02) and Overall (0.03) categories.

Results: Reinforcement Learning Unlocks Smaller, Powerful Models
Below, see the results of our testing across all models, including breakouts for SFT vs PPO on Gemma 4B, Llama 3.1 8B and Mistral 24B Instruct.
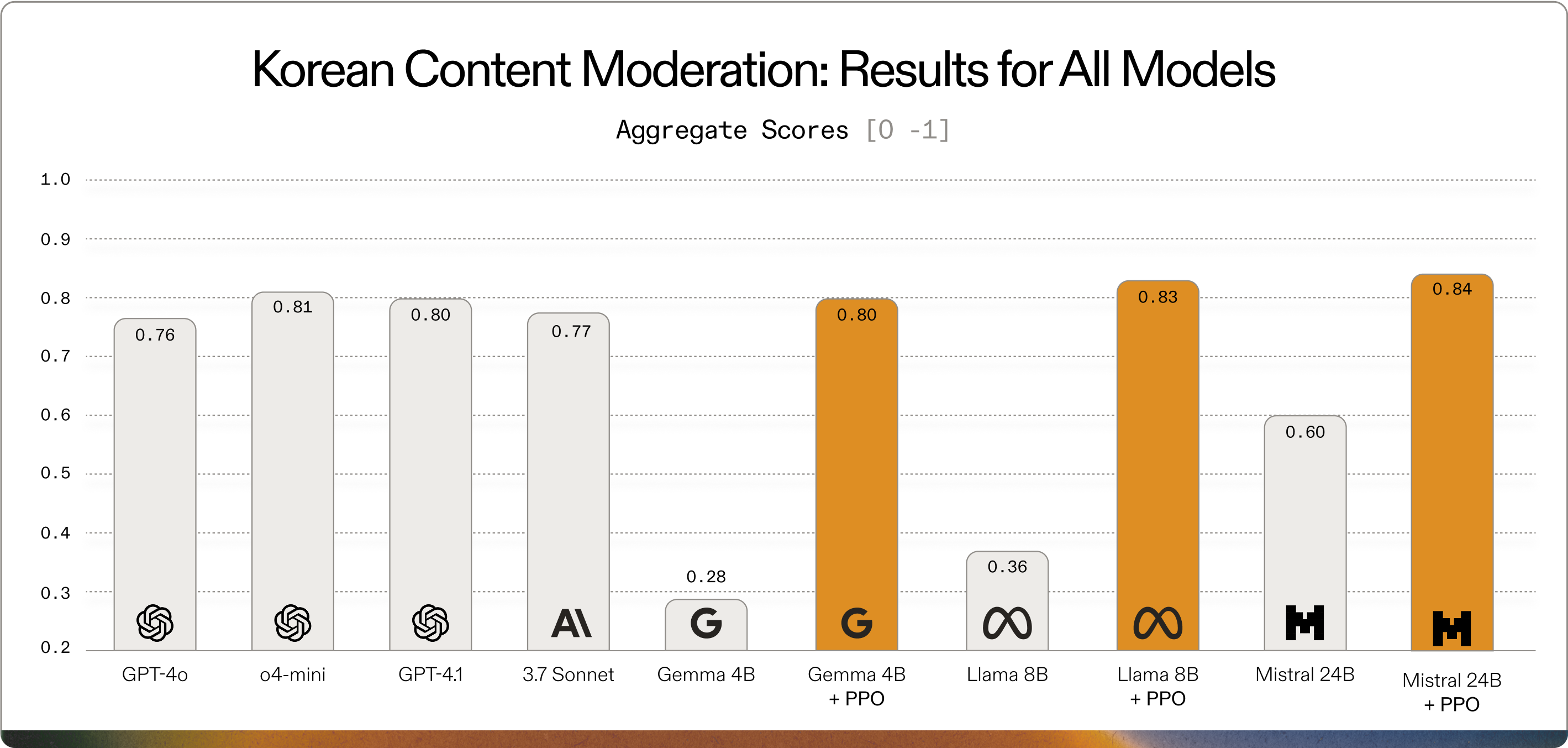
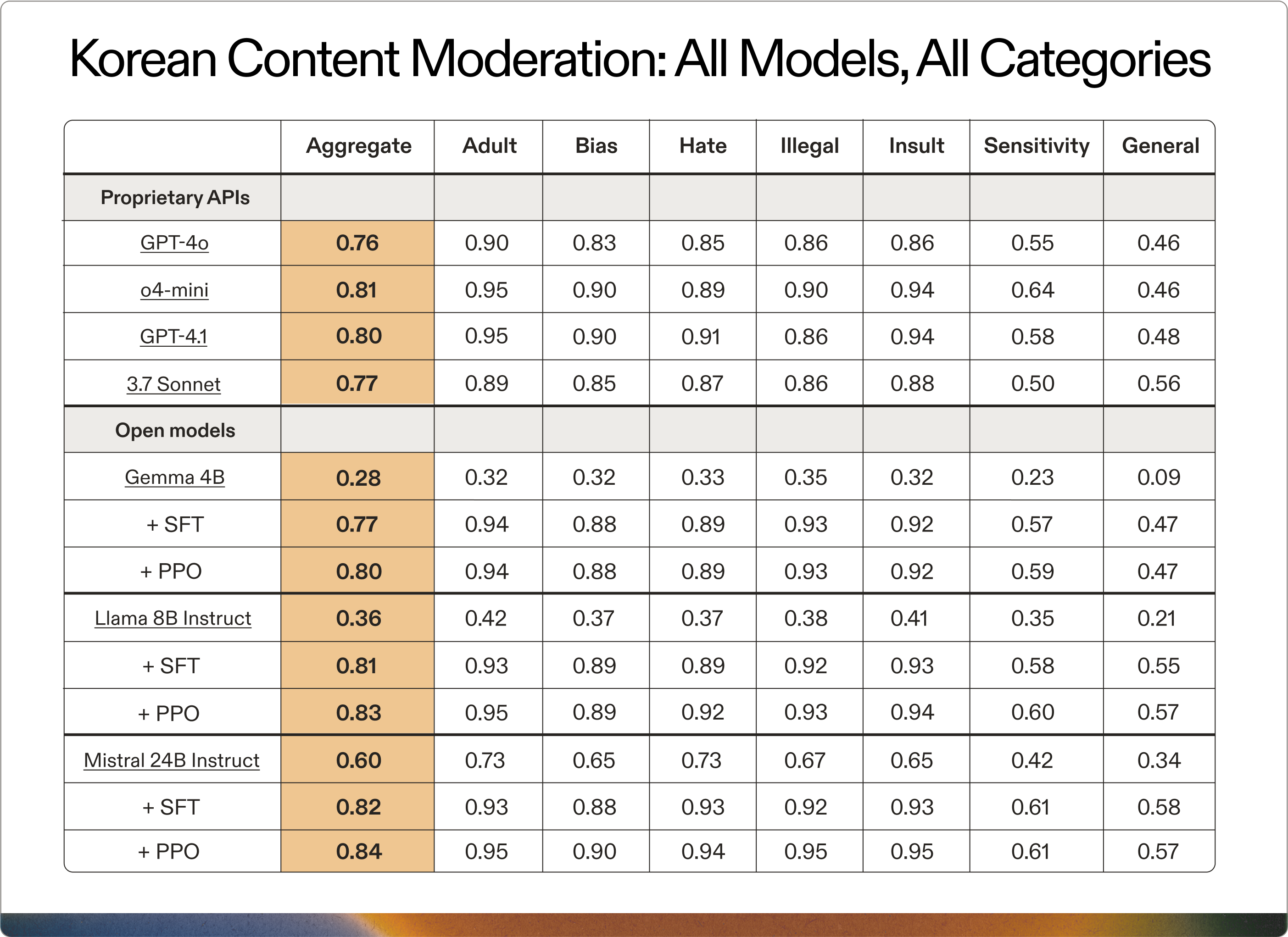
The results of our testing reveal the impressive capabilities of small, open models when properly fine-tuned:
Multilingual Excellence: Performing in Both Korean and English
SK Telecom serves a multilingual community where both Korean and English are prevalent. To ensure their model could effectively moderate content in both languages, SK Telecom provided a similarly-sized English dataset for harmful content detection, and we applied the same training procedure. Unlike the Korean data, the English data contains just a single assessment category: Accuracy.
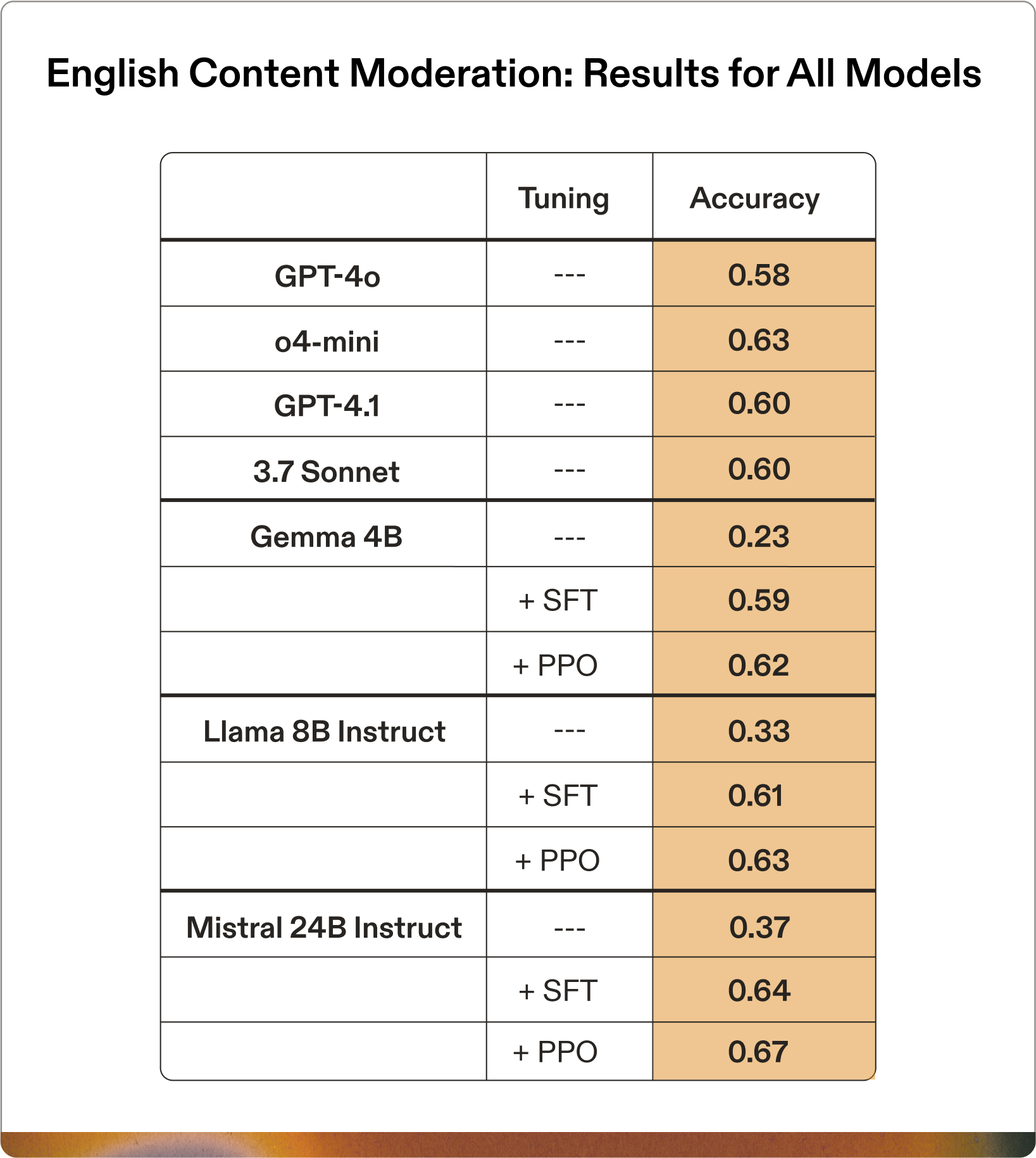
The results for English show nearly identical patterns to those from the Korean dataset. Most importantly, we again see that training with PPO enables a smaller model to match the SFT performance of a much larger model. Gemma 4B trained with reinforcement learning outperforms GPT-4o, GPT-4.1, and Claude Sonnet 3.7—even in their primary language domain. It matches the performance of o4-mini within standard deviation.
“To maintain brand safety and customer trust, we have to understand the intent and cultural context behind the words, not just perform a literal translation. Moderating content in Korean, with its unique idioms and nuance, is a challenge where off-the-shelf APIs often fall short. We were impressed to discover that by using advanced reinforcement learning on a small, open 4B model, we achieved a new level of precision - outperforming even the largest proprietary models in both Korean and English. This is a huge win for strategic control and efficiency; it allows us to deploy a highly accurate, low-latency solution that keeps our customer data secure on-premises, which is critical for maintaining trust.”
Eric Davis, Vice President of the AI Tech Collaboration Group, SK Telecom
Business Impact: Efficiency at Scale
For large enterprises like SK Telecom, the ability to use a 4B parameter model in place of a proprietary API, or even a larger open source model, offers significant savings and huge efficiency gains—particularly at scale. This translates to:
All these benefits come while matching or exceeding the performance of much larger proprietary models.
Adaptive ML is training models for use in the finance, telecommunications, insurance, and mobility industries across RAG, text-to-SQL and customer support workflows. Book a demo of Adaptive Engine today.